A defeat story
I signed up with kaggle.com in 2015 and then completely forgot about it. In April 2019, I moved from MATLAB to Python, and in October 2019, I revived my profile and published two notebooks (Python code in the notebook section of kaggle.com). To kick-off, so to say.
To date, I’ve dedicated 13.5 years to designing mathematical models for the need of the power markets. I’ve modeled processes of production, consumption, and trade of electric power. Kaggle lacks power competitions. I have found only two among hundreds:
- ASHRAE — Great Energy Predictor III (October - December 2019)
- Global Energy Forecasting Competition 2012 — Wind Forecasting (2012)
The first one, ASHRAE — Great Energy Predictor III, was ongoing. People were working on it and the leaderboard was being updated. The idea of the ASHRAE competition is to make a long-term forecast of the energy consumption (electricity, steam, hot and cold water) of 1,500 different buildings located in sixteen areas.
After a long internal discussion, I clicked the join competition button. Why so long? I had a competition experience back in 2010 with the Yandex.ru auto traffic prediction. The competition requires a lot of time and effort. I clicked and… was shocked. For the first time in my power analyst practice, I faced a big data problem:
- input table dimensions are 20M rows by ~16 columns
- output table dimensions are 42M rows by 1 column
In 2019, I spent some meaningful efforts to develop a simple regression model (at least, at that time, I considered it meaningful). I made up fifteen submissions (when you upload your forecast and see how much you’ve scored). As a result, I reached position 2,431 out of 3,614. This was a defeat.
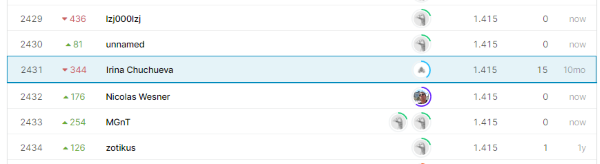
Specifically, my scores were:
- Private Score: 1.415 (2,431/3,416)
- Public Score: 1.185 (2,087/3,416)
Further workout
At the beginning of January 2020, the final leaderboard was published. The winners impressed me with their scores and even more with their openness. Most winners published descriptions of their methodology, listing the models/features/pre- and post-processing algorithms they used. I spent the whole day reading these publications and going through published notebooks and realized that I had to learn from these people. Therefore, I needed to find the time to develop the algorithms/approaches I read about. I set an aim: make 200 late submissions to reach a 10% top score.
From January to June 2020, I dedicated hours and days to solve the ASHRAE problem. The peak activity was in May and the beginning of June.
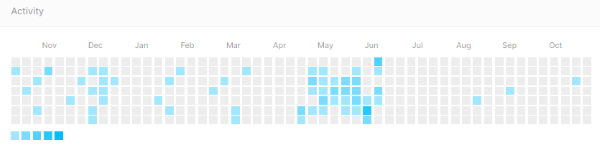
On the competition page, there is a “Late Submission” button that allows you to go on publishing and scoring forecasts after the competition is over. Over five months, I was able to make 158 late submissions and scored ~12%. Details:
- Private Score: 1.291 (558/3,416, 16%) used to be 1.415
- Public Score: 0.964 (269/3,416, 8%) used to be 1.185

The Python framework achieving the score is published on my GitHub page. I have not been able to score better because I signed a new contract at the beginning of June 2020 and have had no time for the ASHRAE problem any longer. I don’t plan to come back to the problem, at least not in the near future.
Here is what I’ve learned from 158 late submission.
Lesson 1: Learn from the best
The ASHRAE competition was a form of self-torture, but also important and fruitful. After 12.5 years of designing mathematical models (by the end of 2019) — in particular power consumption forecast, power price forecast, combine and heat power plant optimization, and others — I thought of myself highly. I have published some titles, including my Ph.D. in time series forecast, I've had other scientific publications with high quotation rates, several successful big projects, a high payment rate, etc.
The ASHRAE competition made me feel miserable. It made me feel like I had fallen from heaven to the ground. Hundreds of people scored much higher and faster than me. Some of them were even facing the power forecast problem for the first time, most of them didn’t have a fraction of my titles, rates, etc.
The struggle with the problem was painful; several times I was almost ready to give up. Here is a part of my letter to my scientific mentor and my friend professor BMSTU Dr. Anatoly Karpenko:
The subject is mine, but the data scope is much bigger than I am used to. Practically It’s impossible to plot everything and look at it with your own eyes. As a result of my skinny November-December 2019 efforts, I had skinny scores. I didn’t give up; I went through a painful period and moved on. I wanted to get good scores and practically understand what it takes to win a Kaggle competition. At first, everything went wrong, and I felt numb and null: “I know nothing!” This was a terrible feeling, especially considering all my experience in the subject. I had the feeling that I was an amateur. That was awful! Absolutely terrible! Despite that feeling, I went further and further. At 50 submissions, I felt like something was starting to work out. It gave me air to breathe and hope. Finally, I’ve completed 158 late submissions, trying to be very precise and consistent and each and every step. At least for the half of submissions, my expectations went away from reality. that it happened, I gave up for a short while. After that short while, I said to myself: “Ok, you expected wrongly, which means that you thought incorrectly. This is the point to learn, analyze, amend your ideas and expectations. And proceed”.
Talented guys and girls, experienced kagglers, monstrous winners — the most qualified and brave participants of the competition made me start from scratch, to feel like a freshman year student, to look at their publications as the methodology, think, repeat, analyze, and score higher. It has been the most sobering experience of my professional life.
Lesson 2: To be best, you need to bag and blend models
During the ASHRAE competition, I heard about LightGBM, CatBoost, and Prophet for the first time. I heard something about XGBoost, but never used the library in practice. I’ve worked intensively with regression and neural network (Python/Keras/TensorFlow).
This is a figure that describes the competition's second-place solution. Site refers to the area.
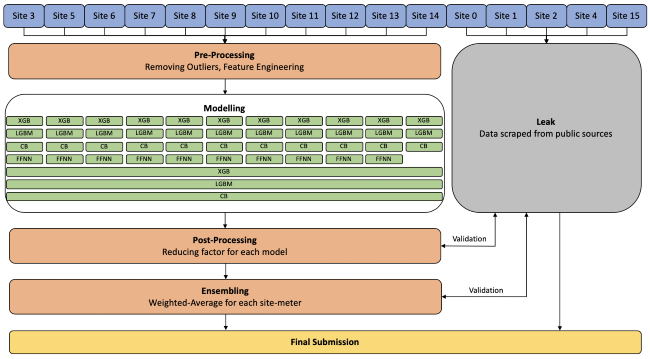
XGB: XGBoost
LGBM: LightGBM
CB: CatBoost
FFNN: Feed-forward Neural Network
That’s my favorite team. They described the solution in detail here. Their solution looks monstrous. To reach second place, they blended around 20K models (see estimation in the comments). Yes, twenty thousand models! They developed several bags with models of the same type (this is called models bagging) and blended them at the ensembling stage.
To gain from blending, you need a long list of the models that are of comparative quality and, also, different from each other to comprise diversity. Diversity can be achieved by using different libraries. This is where Python is in the lead; it has a rich arsenal of mathematical libraries. As I understand, it’s impossible to win a Kaggle competition without a stockpile of precise and diverse models that need to be blended.
Blending can be organized straightforwardly, where the fixed linear coefficient is used (as in the case of second-place solution) for each bag of the models. Alternatively, it can be quite complicated — to get the coefficient the optimization problem is being solved.
In my professional life, I am unable to concentrate for a long time on math only and, as I call it, juggle with numbers to achieve the most accurate solution. At least half of my job is related to comprehending the subject (wholesale power markets); the other half is math-related, of course. The Kaggle competitions allow me to gain number-juggling experience which, in its turn, allows me to do the second half of my job more efficiently. Now, alongside regression and neural network, I have “the wonder boostings” in my arsenal: LightGBM, CatBoost, XGBoost. Working with Prophet, I’ve had disgusting experience.
My 12% score is a simple average for three bags: the first one contains 56 LightGBM models; the second — 24 differently trained LightGBM models; the last one — 18 XGBoost models. Preprocessing: weather linear interpolation; filtering input by removing constant energy values for certain buildings. No postprocessing is done. You may see that there is plenty of room for further improvement compared to the second-place solution.
Lesson 3: Extensive experience is inevitable
While training models as LightGBM, CatBoost, XGBoost, and Neural Network, we face a long list of so-called hyperparameters. For the wonder boostings, I faced it for the first time.
The boosting theory is explained here StatQuest with Josh Starmer. I highly recommend the channel! During the development of my solution, I set the value of the hyperparameters, made an expectation (thinking that I understood what I was doing), and trained the model. At first, the result was poor; my expectation and reality ran in different directions. Then I amended my expectations and edited the value and trained the model again. It was important to alter only one hyperparameter at one step. In the case of multi-altering, you will hardly be able to correctly interpret the score.
My late work consisted of 158 submissions, but most of my train iterations weren’t submitted. Thus, I made 158 * 20M * 3 (let’s assume I submitted every third model) + 158* 42M (late submission itself) = ~16B forecast values.
I consider important the experience of running the model over and over again and understanding hyperparameters' behavior and getting a gut feeling of how the model operates with the given set of numbers. I call that experience extensive. When I was optimizing combine and heat power plants, I ran the optimization model over and over, in the same manner, to better understand how I could tune the model to make it more accurate. Analogously, I spent years on short-term power consumption and price forecasting problems.
The mathematical model for me feels like a car. I need to know exactly how sensitive the wheel and pedals are, where all the buttons-handlers are located, where and how the important numbers are displayed, etc. Then I’ll be able to drive effectively.
To be personally efficient doing my job is critical for me. As a contractor, I usually work four hours a day and push myself hard during these hours. Extensive experience has tiny efficiency though. Thus, it was useful to get practice outside the scope of my current project. My conscience doesn’t allow me to ask to be paid for “playing” models. No, I will play in my spare hours and apply the knowledge for my clients’ projects later.
Kaggle.com provides an immense platform for such an education. The knowledge it provides is highly demanded in the modern world.